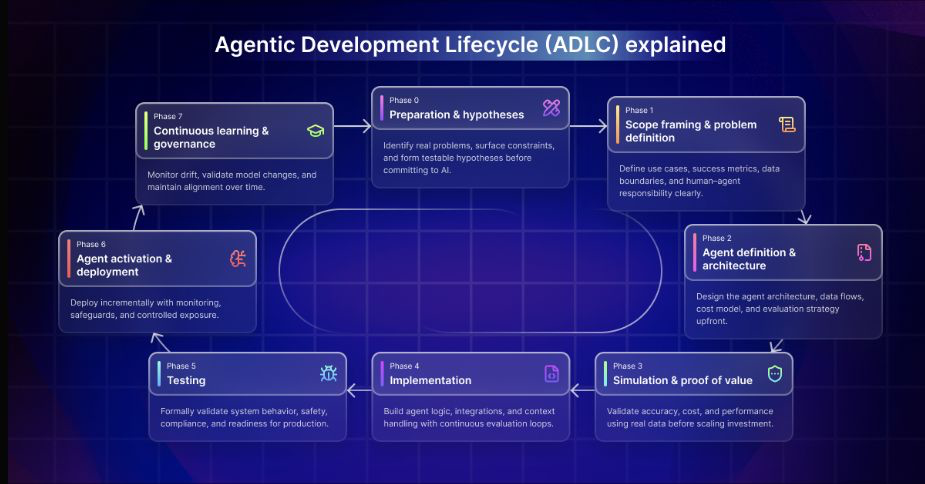
Agentic Development Lifecycle: Stop Shipping Agents Like Normal Apps
Most software delivery models assume the system becomes more stable as it moves toward release.
You clarify requirements, design the architecture, implement the feature, test it, deploy it, then maintain it. Production still has surprises, but the core premise is that behavior is mostly specified before release. The job is to make the implementation match the plan.
Agentic systems do not fit that shape.
An AI agent is not just code. It is code plus prompts, tools, model behavior, retrieval data, memory, policies, user context, and external services. A small change in any of those inputs can change the outcome. The same user request may produce different reasoning on Tuesday than it did last month because the model changed, the knowledge base changed, the tool returned different data, or the user supplied a slightly different context.
That is why EPAM’s article on the Agentic Development Lifecycle is useful. It names a problem many teams are already feeling: agents are not normal applications with a chatbot interface. They are probabilistic systems that keep changing after deployment, so the lifecycle has to treat production as an active control loop instead of a finish line.
SDLC Assumes Stability
The traditional software development lifecycle is still useful. We should not pretend planning, analysis, design, implementation, testing, deployment, and maintenance suddenly stopped mattering.
But SDLC was built around deterministic software. If the same inputs and environment are supplied, the system should produce the same output. Bugs happen, but the goal is clear: identify the wrong branch, bad state, missing validation, race, or integration failure, then fix the code or configuration.
Agents add more moving parts:
- the model’s reasoning path,
- the prompt and system instructions,
- the context assembly layer,
- retrieval quality,
- tool permissions,
- action boundaries,
- memory state,
- safety policies,
- provider behavior,
- user feedback loops.
Some of those are not fully under your control. Some are not even stable over time.
That changes what “done” means. For an agent, passing a test suite before launch is not enough. You need to know how the system behaves across distributions of inputs, how often it escalates, how much it costs per useful outcome, where it hallucinates, when it drifts, and which human owns the decision when confidence is low.
The Real Shift Is From Delivery to Supervision
The most important idea in ADLC is not the phase list. It is the posture.
You stop treating deployment as the point where engineering work becomes mostly reactive. Deployment becomes activation. The agent is now exposed to real variation, real incentives, real user phrasing, real dirty data, and real tool failures. That is when the most important evidence starts arriving.
For normal software, production monitoring often asks:
- Is the service up?
- Is latency acceptable?
- Are errors increasing?
- Are resources saturated?
For agentic software, those questions are necessary but incomplete. You also need:
- Is the answer grounded in the right data?
- Is the agent using tools safely?
- Are refusals appropriate?
- Are users correcting the same mistake repeatedly?
- Is cost per resolved task moving in the wrong direction?
- Are model updates changing behavior?
- Are edge cases accumulating in one workflow?
- Are humans approving actions they should not need to approve?
- Are humans being bypassed where approval is required?
That is supervision, not just maintenance.
Start Before the Prototype
The easiest way to build a bad agent is to start with the agent.
A team sees a repetitive workflow and jumps straight into model selection, orchestration, prompt templates, or a slick demo. The first version looks impressive because demos are narrow and the happy path is carefully chosen. Then the system meets production data and the failure shape changes.
The better first step is slower and less glamorous: define the work.
Before choosing a model, answer:
- What exact workflow is being changed?
- Which step is painful, slow, expensive, or error-prone?
- What decisions can the agent make alone?
- What decisions require human approval?
- What data is authoritative?
- What failure is acceptable?
- What failure is never acceptable?
- What measurable outcome would justify the system?
This is where many agent projects become honest. A large portion of “we need an agent” requests are really process problems, data quality problems, or unclear ownership problems. An agent can still help, but only if the team names the boundary.
An agent without a boundary becomes a liability. It will accept work that should have been refused, improvise where it should escalate, and create output that looks plausible enough to delay detection.
Design the Responsibility Model
The most underrated artifact in agent projects is the human-agent responsibility map.
Every production agent needs clear answers to four questions:
- What can the agent decide?
- What can the agent recommend but not execute?
- What must be reviewed by a human?
- Who is accountable when the system is wrong?
This matters more than the architecture diagram.
Architecture tells you how the agent is built. Responsibility mapping tells you where authority lives. Without that, the system’s actual policy becomes whatever the prompt, UI, and operational pressure happen to allow.
For example, a customer support agent might be allowed to summarize account history, draft replies, and classify refund requests. It might not be allowed to approve refunds above a threshold, alter billing details, or make legal commitments. A security triage agent might be allowed to gather evidence and propose severity, but not close a critical incident without human confirmation.
These are not implementation details. They are product and risk decisions.
Build Evals Before You Trust the Build
Agent development has a dangerous failure mode: the system feels good in manual testing.
You try ten examples. Seven are strong, two are acceptable, one is weird but easy to explain away. The demo is convincing. The team ships.
That is not enough.
Agent quality is distributional. You need a representative set of cases that includes normal inputs, ambiguous inputs, adversarial inputs, stale data, missing data, policy conflicts, tool failures, and edge cases from real operations.
That dataset becomes a permanent asset. It is not just a proof-of-value artifact. It becomes the regression suite for prompt changes, model upgrades, retrieval changes, tool changes, and policy changes.
Useful evals should measure more than “did the answer look good?”
Track things like:
- task success rate,
- groundedness,
- hallucination rate,
- escalation quality,
- unsafe action attempts,
- latency,
- token and tool cost,
- user correction rate,
- policy compliance,
- recovery after tool failure.
The key is to evaluate the behavior you actually need, not the behavior that is easiest to score.
Implementation and Evaluation Are One Loop
In normal software, teams often write code first and test later. That can work when behavior is deterministic and the unit boundaries are stable.
With agents, that split breaks down. A prompt edit, retrieval tweak, tool schema change, or memory policy adjustment can change behavior across the whole workflow. The feedback loop has to be tight.
A practical implementation loop looks like this:
- Make one small behavioral change.
- Run the eval set.
- Inspect failures, not just aggregate score.
- Update prompts, context, tools, or data.
- Run the eval set again.
- Promote only when the change improves the target behavior without breaking safety or cost thresholds.
This is why eval infrastructure becomes part of the development environment. If the evals are slow, hard to run, or disconnected from developer workflow, they will be skipped. Once they are skipped, agent changes become vibes with logs.
Deployment Is a Controlled Activation
Agents should rarely go from staging to everyone.
Use the same operational discipline you would use for risky infrastructure changes:
- phased rollout,
- canary users,
- feature flags,
- clear rollback path,
- cost limits,
- rate limits,
- audit logging,
- escalation triggers,
- human override.
But add agent-specific observability.
You need visibility into prompts, retrieved context, tool calls, model versions, intermediate reasoning artifacts where appropriate, final outputs, user feedback, and intervention points. You also need privacy and security controls around that telemetry because agent traces often contain sensitive business context.
The goal is not to collect everything forever. The goal is to preserve enough evidence to understand why the agent acted the way it did.
If you cannot reconstruct a bad decision, you cannot improve the system with confidence.
Governance Is Not a Quarterly Review
The uncomfortable truth about agents is that they can degrade without a code deployment.
The model provider changes behavior. Users learn how to phrase requests differently. A knowledge base goes stale. A tool API changes. A new policy is introduced. A previously rare edge case becomes common. The agent’s operating environment moves.
So governance has to be continuous.
A serious operating model includes:
- scheduled eval runs against current model versions,
- regression checks before model upgrades,
- review of low-confidence and escalated cases,
- cost monitoring by workflow,
- periodic knowledge base refreshes,
- prompt and policy versioning,
- incident review for agent failures,
- retirement criteria for workflows that no longer justify automation.
This is not bureaucracy for its own sake. It is how you keep a non-stationary system aligned with a changing business.
A Practical ADLC Checklist
If I had to compress ADLC into a usable checklist for a team building a production agent, I would use this:
- Define the workflow before defining the agent.
- Write down the agent’s authority boundaries.
- Identify the human owner for every high-risk decision.
- Create a representative eval dataset from real work.
- Measure behavior, cost, safety, and escalation quality.
- Treat context and data quality as part of system logic.
- Run evals during development, not only before release.
- Deploy gradually with observability and rollback.
- Monitor drift, user corrections, and model changes after launch.
- Keep governance tied to real failure signals, not abstract policy theater.
That checklist is less exciting than a demo. It is also the difference between an agent that survives production and one that becomes a liability the moment the inputs stop being curated.
The Point
ADLC is not “SDLC plus AI tools.” It is a lifecycle for systems where behavior is partly learned, partly prompted, partly retrieved, partly tool-driven, and partly controlled by external model providers.
That means engineering control has to move up a level.
The winning teams will not be the ones with the longest prompt library or the flashiest agent framework. They will be the ones that can define authority, build evals, observe behavior, manage drift, and improve the system continuously without losing accountability.
Agents make software more adaptive. ADLC is the discipline that keeps that adaptability from turning into unmanaged risk.